Attribute FAQs
You can create and update attributes to provide more information about XML elements you use in your content.

- What is the difference between an element and an attribute?
- Why not just create a new element?
- Why would I want an attribute to be profiled?
- Why do I need an attribute that is a component identifier?
- Why do I need an attribute that is a language identifier?
- Why would I want to protect an attribute?
- Where can users select the attribute after I add it?
- Where do administrators manage attributes?
What is the difference between an element and an attribute?
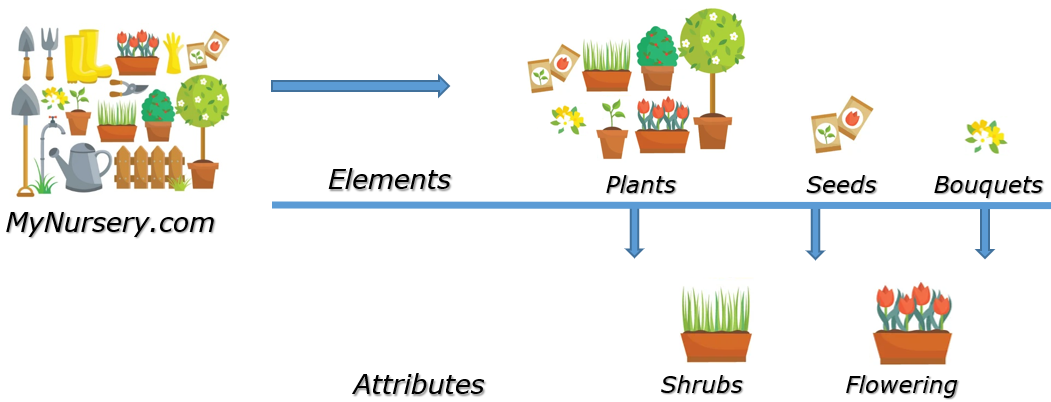
Elements represent data. They're typically used when the data:
- Has structure
- Needs to be extended
In the example diagram above, if you owned a plant nursery, you could have an element to hold the name each item you sell in your nursery.
The elements in this example are:
<Plants>,<Seeds>and<Bouquets>The element's content could be
Yew bush,Sunflower,Roses
Attributes provide metadata or additional information about the elements. They describe properties of the plant, seeds, and bouquets but aren’t standalone pieces of content like <plant> is.
The attributes in this example are:
<Shrubs>and<Flowering>The
<Shrubs>attribute content could beDeciduous,Evergreen- The
<Flowering>attribute content could beAnnual,Perennial,Biennial
 In Inspire, an example would be a paragraph (P) or list item (li) element, and an attribute would be a link to a website (href).
In Inspire, an example would be a paragraph (P) or list item (li) element, and an attribute would be a link to a website (href).
Why not just create a new element?
In XML, you can use attributes or a nested element to describe your data.
When to use what?
- Use elements for information that could stand alone or might have child elements.
- Use attributes for metadata, flags, or simple properties unlikely to need extra structure.
Inspire provides the Oxygen editor and a user-friendly interface for selecting Attributes easily.
If you want to only use elements:
- You must author content directly in the XML code.
- You would replace attributes (
<Shrubs>and<Flowering>) with separate elements inside<Plants>,<Seeds>and<Bouquets>. - This method is this preferred when the data is complex.
- This method can make the XML bulkier if simplicity is desired.
Why would I want an attribute to be profiled?
Profiling text is a way to mark blocks of text meant to appear in some renditions of the document but not in others.
- DITA offers support for using conditional text through profiling attributes.
- You can define your own values for the DITA profiling attributes or use the default values provided by Inspire.
- Marking an attribute as Profiled means it can be used in the Oxygen editor as a profiling attribute tag that describes the conditional text to be shown or hidden.
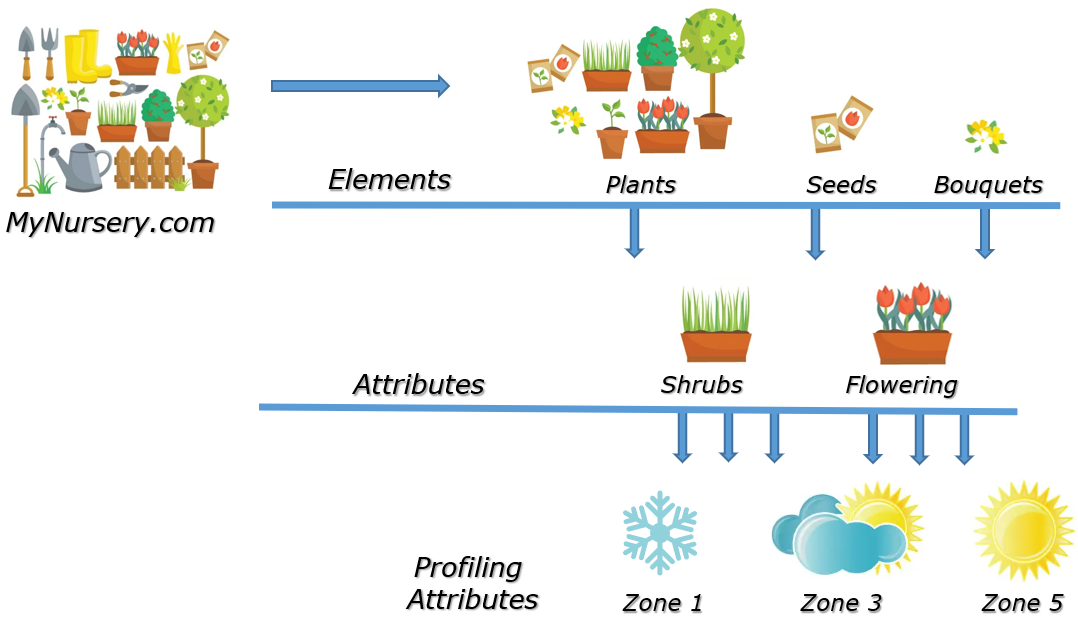
For example, when you create an attribute for Zone1, you can select the Profiled option. This means when you are creating content, you can mark a section of a document that is to be included for shrubs in a freezing climate only, while unmarked sections are included in all versions of the document.
- If you want to publish a version of the document for zone 1 only, you would select the Zone 1 profiling attribute when publishing. This will hide any text that is tagged as Zone 3 and Zone 5.
- If you want to publish a version of the document for zones 3 and 5 only, you would select the Zone 3 and Zone 5 profiling attribute when publishing. This will hide any text that is tagged as Zone 1.
You can use conditional text when you develop documentation for:
- A series of similar products
- Multiple releases of a product
- Various audiences
The benefits of using conditional text include reducing the effort for updating and translating your content, and providing an easy way to customize the output for various audiences.
When creating or updating an attribute, an administrator can specify that this attribute can be used to identify conditional text by selecting Profiled.
- The Profiled option is not selected by default.
- If you do not want to use an attribute to profile content, you can leave the Profiled option unselected.
- If you select the Profiled option, the attributes are listed on the Profiling Attributes screen for you to select and apply to text in the Oxygen editor.
In Inspire, an example would be an attribute for audience, and profiling values would be beginner, intermediate, and advanced.
For more help on creating profiled attributes, read: Allow an attribute to be used for profiling.
Why do I need an attribute that is a component identifier?
To store a unique ID that identifies the DITA and DocBook Schema Standards.
While XML is a flexible markup language that allows you to define custom tags, DITA (Darwin Information Typing Architecture) provides a set of predefined tags for creating structured documentation.
- DITA's structure is optimized for topic-based authoring, which is absent in general-purpose XML schemas.
A DITA schema standard is a set of rules and specifications for structuring and organizing technical documentation using XML.
- When authors are creating content, they can use the features in the schema standard you are using.
- For example, some versions of DITA schemas and how they differ:
DITA 1.2: Approved in December 2010, this version introduced key features like indirect linking with keys, enhanced glossary support, and new industry specializations like Training and Machinery.
DITA 1.3: Approved in December 2015, this version adds features such as branch filtering, the troubleshooting topic type, scoped keys, and support for MathML and SVG.
Inspire tags components with the schema standard you are using to create your documentation by storing the schema version in the Identifier attribute.
 Rules for component identifiers:
Rules for component identifiers:
- There must be only one attribute that is the DITA component identifier.
- Inspire provides one for DITA (
<id>). - If you want to create your own component identifier attribute for DITA, you must update the default attribute to clear the Identifier option.
- Inspire provides one for DITA (
- There must be only one different attribute that is the DocBook component identifier.
- Inspire provides one for DocBook (
<xml:id>). - If you want to create your own component identifier attribute for DocBook, you must update the default attribute to clear the Identifier option.
- Inspire provides one for DocBook (
- It is not possible for an attribute to be both a component identifier and a language identifier.
For more help on creating attributes as component identifiers, read: Create an attribute to be a component identifier.
Why do I need an attribute that is a language identifier?
To store a unique ID that identifies the language a component's content is written in.
In DITA, you need a language identifier, specifically the <lang> attribute, primarily for the following reasons:
- Facilitating Translation and Localization: Specifying the language of your content using the
<lang>attribute is crucial for efficient translation workflows. Translation tools and processes rely on this attribute to properly identify the source language and ensure accurate translation into the target language. - Enabling Automatic Processing and Styling: DITA processors, such as the DITA Open Toolkit, use the
<lang>attribute to process and style content appropriately for the specified language and locale. Without it, processors may assume a default language which could lead to incorrect output. - Enhancing Content Portability and Reuse: By clearly marking the language of content, you ensure greater portability and reuse of your DITA files. This makes it easier to manage and update multilingual documentation sets, as the language boundaries are clearly defined, according to the Oxygen XML editor.
You should explicitly set the <lang> attribute on the root element of each map and topic, even for single-language documents.
- This establishes the primary language of the content and helps prevent potential issues during processing or future localization efforts.
- If a document contains content in multiple languages, the primary language should be set on the highest-level element, and any sections or elements containing text in a different language should have the
<lang>attribute set appropriately to override the default.
Inspire can store the language you are using to create your documentation in the following ways:
- Components: Inspire uses the
<xml:lang>attribute- If the Language you are using is French, this value is stored in
<xml:lang> - This
<lang>identifier is added to all elements in the component
- If the Language you are using is French, this value is stored in
Rules for language identifiers:
- There must be only one attribute that is the language identifier.
- Inspire does NOT provide a default language identifier attribute.
- You can create your own language identifier attribute as long as no other attribute already uses attribute to the Language option.
- It is not possible for an attribute to be both a language identifier and a component identifier.
For more help on creating attributes as component identifiers, read: Create a language identifier attribute.
Why would I want to protect an attribute?
To ensure the stability, maintainability, and reusability of your content.
In Inspire, you can configure an attribute to be protected for the following reasons:
- Respecting the intended use and constraints of the attribute, particularly for architectural and processing-related attributes
- Controlling the set of allowed values for attributes to ensure consistency and correct processing
- Utilizing DITA's mechanisms like subject scheme maps and DITAVAL files to manage attribute values and conditional processing effectively
In Inspire, administrators can create or update an attribute and mark it as Protected:
- By default, the Protected option is not selected.
- You can select Protected in conjunction with any other property such as Profiled, Identifier, or Language.
If an attribute has the Protected property :
In the Oxygen editor, to delete or update protected attributes, users must have one of the following permissions:
Permissions to the can_modify_protected_attributes property
- Administrator
This protection is enforced in the Oxygen editor in the following places:
Author mode
Edit XML Source mode
- Reviews
- Resolving reviews
For example, your documents have a Related Information section where there must be at least one link to your home marketing website.
- An administrator would update the href attribute and select the Protected option.
- Users who are not administrators and are working in documents with a Related Information section would not be able to delete any hrefs, or change the website URL stored in the href attribute.
- If you want specific users or a role to be able to delete or update the href in Oxygen, you can grant them permissions to the Content Browser module property, can_modify_protected_attributes.
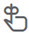 Keep the following issues in mind when marking an attribute as protected:
Keep the following issues in mind when marking an attribute as protected:
- Some attributes, like
<class>, are architectural attributes and should not be directly edited by authors. They define the element's specialization hierarchy and are crucial for DITA tools and processors to function correctly. Altering these attributes can lead to incorrect processing or validation errors. - Many attributes benefit from having a controlled set of allowed values. Having a locked set of values helps authors choose appropriate values. This promotes consistency and accuracy across the documentation. It also prevents incorrect formatting or interpretation by the build process.
- Subject scheme maps can define controlled values for profiling attributes without requiring specialization or constraints, making it easier to manage and modify these values quickly.
For more help on creating protected attributes, read: Work with protected attributes.
Where can users select the attribute after I add it?
Users can select this attribute in the Oxygen editor in the  Attributes pane on the right side.
Attributes pane on the right side.
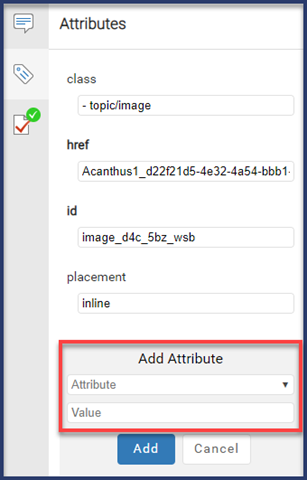
 If you select the Profiled option for the attribute, then users can select the attribute from the lists on the profiling attributes screens.
If you select the Profiled option for the attribute, then users can select the attribute from the lists on the profiling attributes screens.
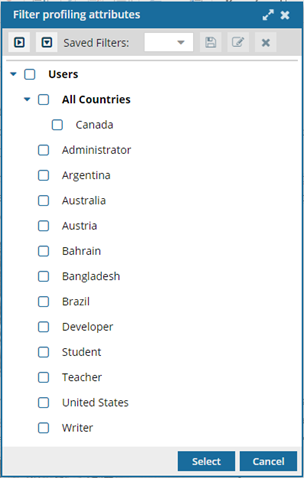
Where do administrators manage attributes?
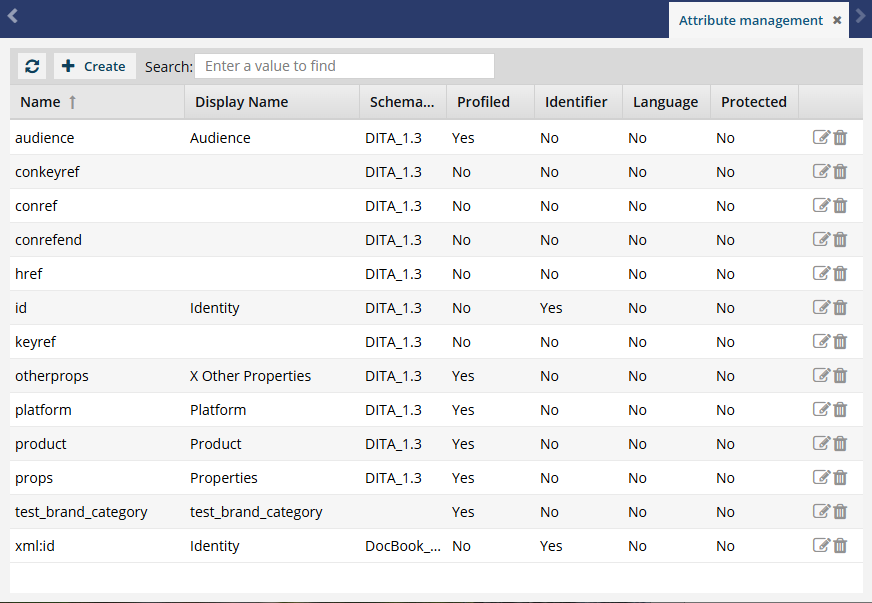
Administrators can view, create, update, and delete attributes on the Attribute Management screen.
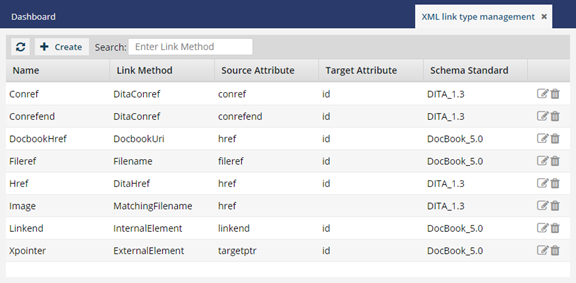
Administrators can select the attribute from the lists on the XML Link Type Configuration screens.